ICCV2019论文,实现了ARM平台上的第一个实时检测器和最快的单线程速度。知乎上有论文讲解,可以参考。
现有方法(当然我没有看过相关论文)有one-stage和two-stage,one-stage在精度上显然会更差;two-stage在时间上更久。现有的实时检测网络大多是基于one-stage的。MobileNet和ShuffleNet是经常采用的检测backbone,但是这些backbone来源于classification,对于检测并不是最优的。
- Backbone的设计思路
背景:大的感受野有助于提供全局信息,在分割和检测中是重要的;在backbone中,浅层信息和深层信息都很重要(这个和SR是一致的)
将shufflenetV2的3x3卷积替换成5x5,这里感受野变大但是计算速度没有大太多
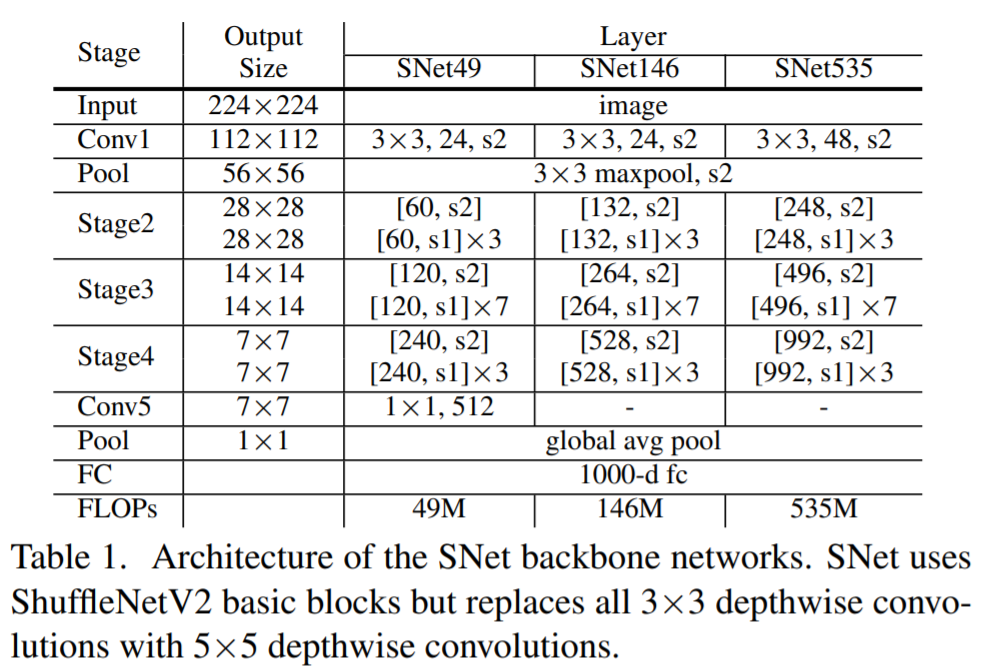
- 作者在ShufflenetV2的基准下,结合上述特性对ShufflenetV2进行修改并命名为SNet。如下图所示,作者给出了集中不同形式的SNet网络。
- Context Enhancement Module
- Light-Head R-CNN网络中在骨干网络之后利用GCN:Global Convolutional Network产生更小的特征图,这虽然增加了感受野但却提升了计算复杂度,因此在本文提出的网络中没有使用GCN。然而,感受野小且在没有GCN的情况下网络很难提取到足够的可分辨的特征信息。 为了解决这个问题,本文使用了特征金字塔网络(FPN)。 然而,原始的FPN结构涉及许多额外的卷积和多个检测分支,这增加了计算成本并且引起了巨大的运行时间延迟。因此,基于FPN,本文提出了Context Enhancement Module (CEM),示意图如下。
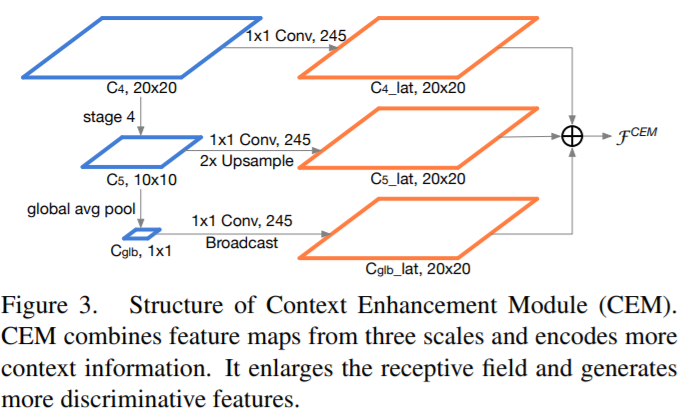
- 通过利用局部和全局信息,CEM有效地扩大了感受野,并细化了薄特征图的表示能力。与先前的FPN结构相比,CEM仅涉及两个1×1卷积和fc层,这更加计算友好。
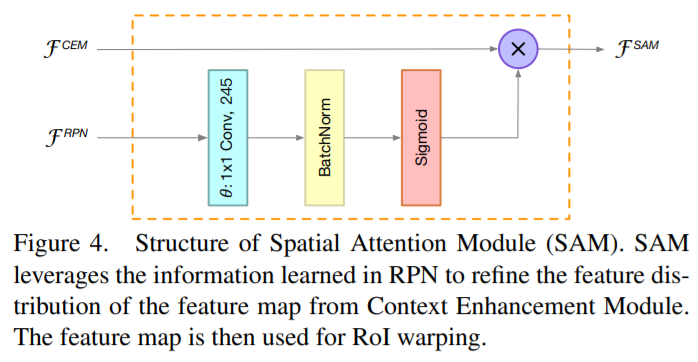
- Spatial Attention Module
- 在进行RoI操作的时候,我们期望背景区域中的特征不被关注,且前景物体的特征被强烈关注。 然而,由于本文的检测网络利用的是轻量级骨干网络和小分辨率输入图像,因此很难学习到正确的特征分布。出于这个原因,作者设计了一个计算友好的空间注意模块(SAM),以便在RoI扭曲空间维度之前显式地重新加权特征图,引导网络学习到正确的前景背景特征分布。SAM的关键思想是使用来自RPN学习到的知识来细化特征图的特征分布。因为训练RPN网络时,网络就是以前景目标作为监督来训练的。 因此,RPN网络可以用于区分前景特征和背景特征。