中科大《GPU并行计算和CUDA程序开发及优化》课程笔记,授课教师:谭立湘。
绪论
GPU计算强控制弱,更多的资源用于数据计算;CPU强控制弱计算,更多的资源用于缓存。在使用GPU计算前,CPU必须先将数据传到GPU显存中;在GPU计算完成后,GPU再将结果数据返回给主机内存。CPU和GPU的通信尤其重要!!
并行计算基础
并行计算
时间上并行(流水线)+空间上并行(矩阵分块)
并行计算的三个基本条件
- 并行机(包含多个处理器核心+通过特定硬件相互连接、相互通信)
- 问题具有并行度,可以分解为多个可以并行执行的子任务
- 并行编程
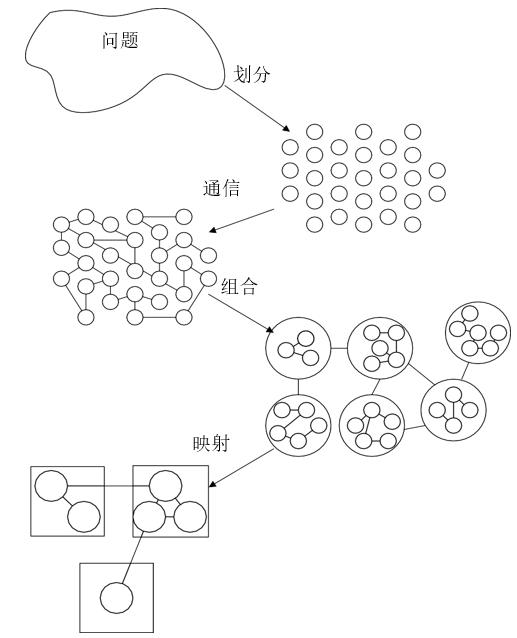
PCAM设计方法
设计并行算法的四个阶段:
- 划分(Partitioning);分解成小的任务,开拓并发性
- 又分为域分解和功能分解
- 域分解的对象是数据,如果一个任务需要别的任务中的数据, 则会产生任务间的通讯
- 功能分解划分的对象是计算,将计算划分为不同的任务;划分后研究不同任务所需的数据,数据应当不相交
- 通讯(Communication):确定诸任务间的数据交换,检测划分的合理性
- 划分产生的多个任务不能完全独立执行,需要在任务间进行数据交流; 功能分解确定了任务之间的数据流
- 分为局部/全局通讯、结构化/非结构化通讯、静态/动态通讯、同步/异步通讯
- 组合(Agglomeration):依据任务的局部性,组合成更大的任务
- 组合是由抽象到具体的过程,是将组合的任务能在一类并行机上有效的执行
- 合并小尺寸任务,减少任务数。如果任务数恰好等于处理器数,则也完成了映射过程
- 通过增加任务的粒度和重复计算,可以减少通讯成本
- 映射(Mapping):将每个任务分配到处理器上,提高算法的性能
- 每个任务要映射到具体的处理器,定位到运行机器上
- 任务数大于处理器数时,存在负载平衡和任务调度问题
- 映射的目标:减少算法的执行时间
- 划分(Partitioning);分解成小的任务,开拓并发性
原则
先尽量开发算法的并发性和扩展性,其次考虑通信成本和局部性,再次利用局部性相互组合减少通信成本,最后将组合后的任务分配到各个处理器并行算法复杂性度量
- 指标
- 运行时间t(n): 包含计算时间和通讯时间,分别用计算时间步和选路时间步作单位。n为问题实例的输入规模。
- 处理器数p(n)
- 并行算法成本c(n): c(n)=t(n)p(n)
- 总运算量W(n): 并行算法求解问题时所完成的总的操作步数
- 设计并行算法时应尽可能地将每个时间步的工作量均匀地分摊给p台处理器,使各处理器处于活跃状态—- 负载均衡
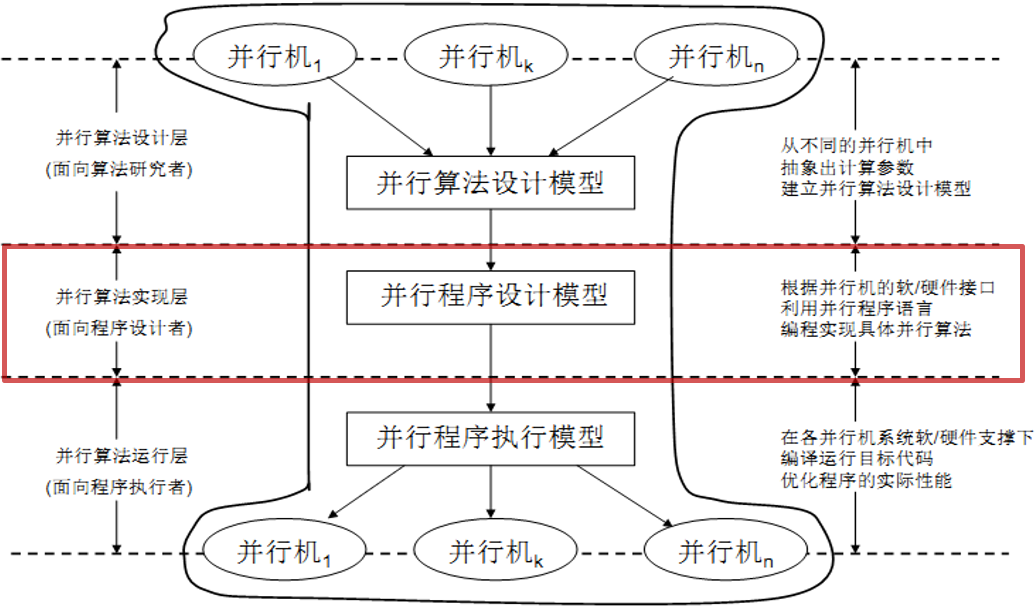
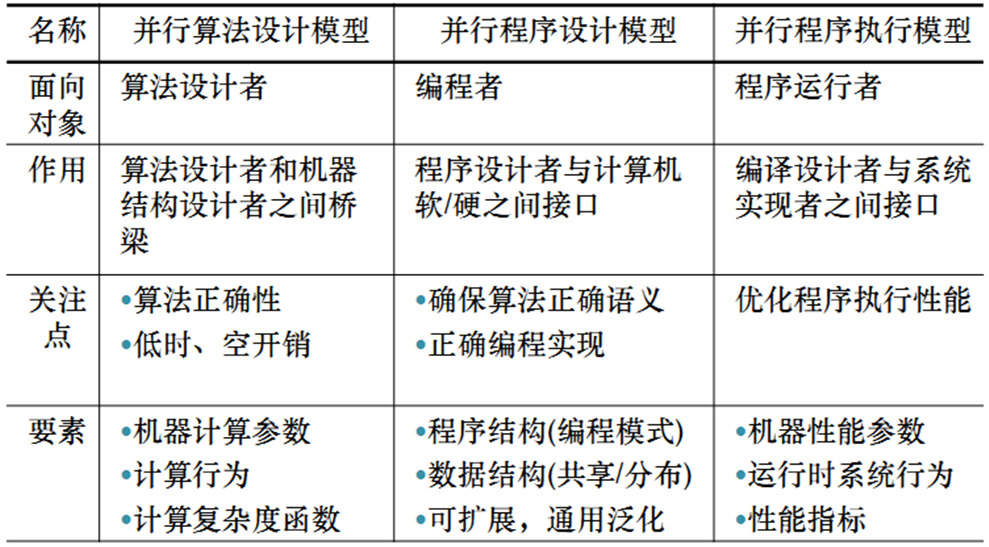
- 三层并行计算模型
- 指标
并行算法设计
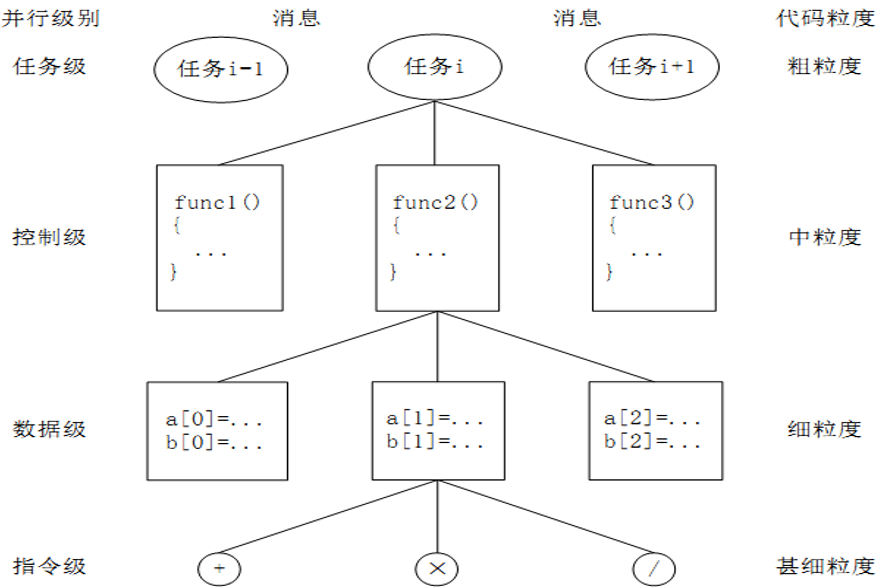
。。。不写了,和本科学的操作系统有关并行层次和代码粒度
OpenMP并行编程
OpenMP并行编程模型
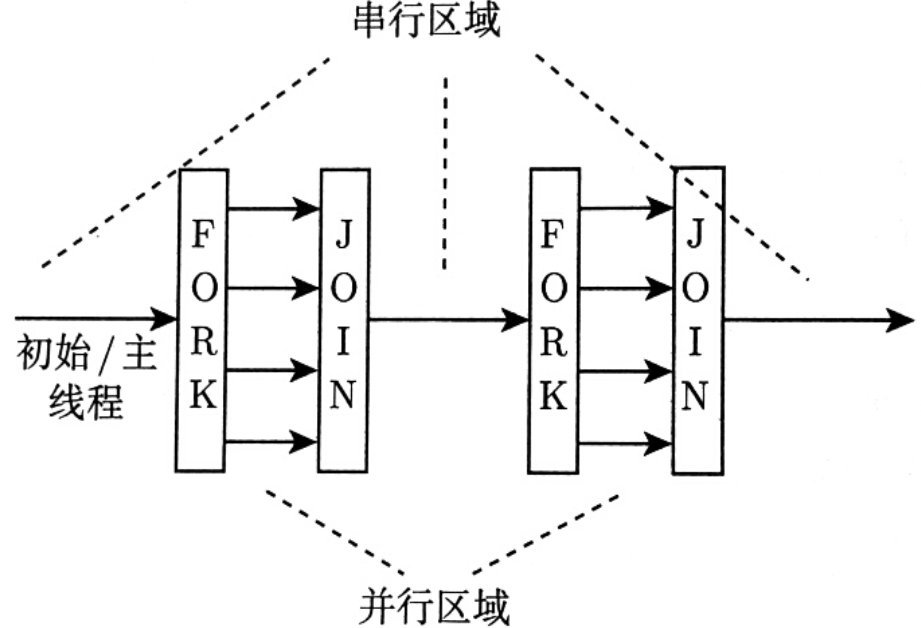
程序开始时只有一个主线程,程序中的串行部分都是由主线程执行;并行的部分是通过派生其它线程来执行。但是如果并行部分没有结束时是不会执行串行部分的。
GPU 硬件架构
GPU体系结构相关术语
- SP(Streaming Processor):流处理器是GPU运算的最基本计算单元。
- SFU(Special Function Unit):特殊函数单元 用来执行超越函数指令,比如正弦、余弦、平方根等函数。
- Shader core(渲染核/着色器),SP的另一个名称,又称为CUDA core,始于Fermi架构
- DP (双精度浮点运算单元)
- SM(Streaming Multiprocessors):流式多处理器是GPU架构中的基本计算单元,也是GPU性能的源泉,由SP、DP、SFU等运算单元组成。这是一个典型的阵列机,其执行方式为SIMT(单指令多线程),区别于传统的 SIMD(单指令流多数据流),能够保证多线程的同时执行
SMX: Kepler架构中的SM - SMM: Maxwell架构中的SM
- TPC(Thread Processing Cluster)线程处理器簇:由SM和L1 Cache组成,存在于Tesla架构中。
- TPC(Texture Processing Cluster)纹理处理器簇:出现在Pascal架构中。
- GPC(Graph Processing Cluster)图形处理器簇:类似于TPC,是介于整个GPU和SM间的硬件单元,始于Fermi构架。
- SPA(Scalable streaming Processor Array)可扩展的流处理器阵列:所有处理核心和高速缓存的总和,包含所有的SM、TPC、GPC。与存储器系统共同组成GPU构架。
- MMC(MeMory Controller)存储控制器:控制存储访问的单元,合并访存。每个存储控制器可以支持一定位宽的数据合并访存。
- ROP(raster operation processors)光栅操作单元
- LD/ST(Load/Store Unit)存储单元
GPU计算能力
需要区分计算能力和运算性能两个概念:- 运算性能包括整数运算性能、单精度浮点运算性能和双精度浮点运算性能等,表示GPU处理算术运算的能力,也是衡量GPU好坏的关键指标之一
- 计算能力是指GPU架构或GPU支持的功能,而与GPU的浮点运算性能无关
几种架构
- 几种典型架构
- Tesla架构的SM
由8个SP、2个SF和一个执行双精度运算的DP组成,同时还包含了寄存器、共享存储、常量存储等单元
- Tesla架构的TPC
2~3个SM配合L1 Cache构成TPC,Tesla架构主要核心型号有G80和GT200.每个TPC均由一个SM控制器进行统一控制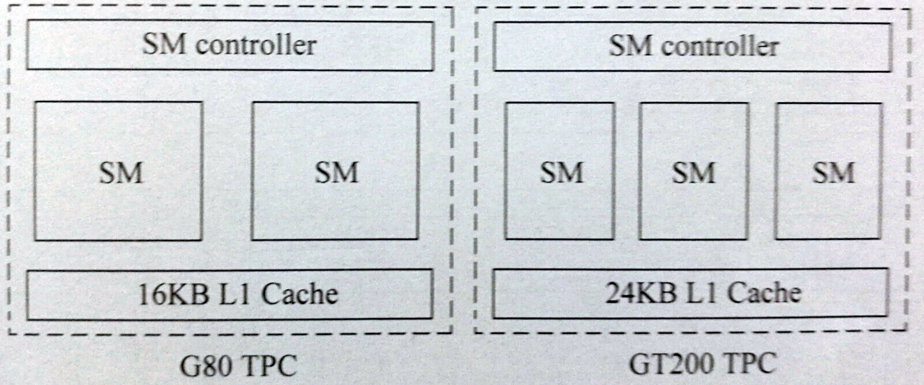
- Tesla架构的G80
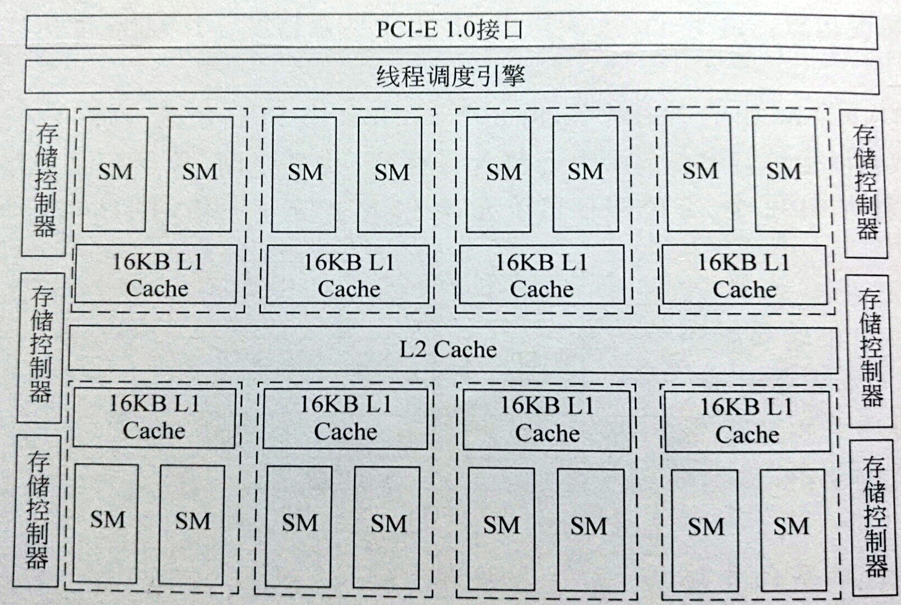
- Tesla架构的GT200

- Tesla架构的SM
- 后面讲的全是GPU体系结构,感觉挺枯燥的,也不想做老本行了,算了就不看了叭
GPU 软件体系及CUDA编程模型
GPU软件体系
- 编译器
- NVCC(NVIDIA CUDA Compiler)
- 编程模型
- CUDA (CUDA C、CUDA Python、CUDA Java、CUDA C++、CUDA.NET)
- OpenCL
- OpenACC
- 数学库函数
- 包括但不限于:线性代数库CUBLAS、快速傅里叶变换CUFFT、深度学习CUDNN、FFmpeg
- 性能分析工具
- NVIDIA Visual Profiler
程序调试工具
管理软件
- nvidia-smi
- 代码实例及使用文档
CUDA软件
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由 NVIDIA 推出的通用并行计算架构,该架构使 GPU 能够解决复杂的计算问题。 它包含了 CUDA 指令集架构(ISA)以及 GPU 内部的并行计算引擎。CUDA 是一个全新的软硬件架构,可将 GPU 视为一个并行数据计算的设备,对所进行的计算进行分配和管理,无需将其映射到图形 API
CUDA的基本思想是支持大量的线程级并行,并在硬件中动态地调度和执行这些线程。GPU与CPU协同工作,GPU只有在计算高密度数据并行任务时才发挥作用!!![]()
GPU软件体系
分为三层结构:CUDA函数库、CUDA运行时API、CUDA驱动API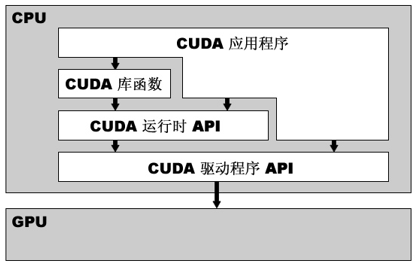
宿主代码和设备代码
基于 CUDA 开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在 GPU 开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。CUDA 所提供的运行期环境是通过驱动来实现各种功能的。CUDA软件环境
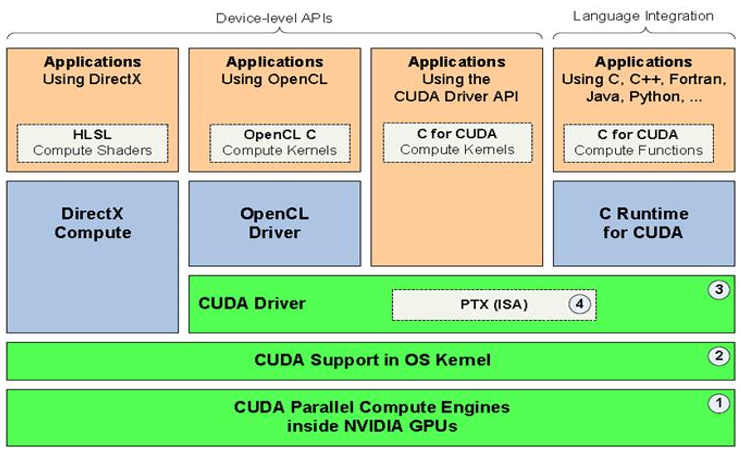
CUDA最主要的包含两个方面: ISA指令集架构与硬件计算引擎;实际上是硬件和指令集。见下图中的绿色部分,CUDA 架构的组件组成是:- NVIDIA GPU中的并行计算引擎;
- 对硬件初始化、配置的OS内核级支持;
- 用户模式的驱动,为开发者提供设备级的API;
- 用于并行计算 kernel函数 的PTX 指令集架构(ISA,Instruction set architecture)
CUDA编程术语
kernel函数
Kernel函数是指为GPU设备编译的一个函数。也就是一个编译好的、在GPU上并行运行的计算函数。Kernel在GPU上以多个线程的方式被执行 。一个完整的CUDA程序是由一系列的设备端kernel函数并行部分和主机端的串行处理部分共同组成的。这些处理步骤会按照程序中相应语句的顺序依次执行,满足顺序一致性。Host,宿主,CPU、系统的CPU
负责启动应用程序,运行程序的串行部分,将程序的并行、计算密集的部分offload到GPU上运行,并最终返回程序的运行结果。Device,设备,GPU,CPU的协处理
负责程序的并行、计算密集部分的处理,并将处理结果返回给Host。Host Memory:宿主内存
是指安装GPU产品的主机的主板板载内存device Memory:设备内存
GPU设备的板载内存(显卡的显存),是高性能的 GDDR5 内存,支持DMA访问Block:线程块
执行Kernel的一组线程组成一个线程块。一个线程块最多可包含1024个并行执行的线程,线程之间通过共享内存有效地共享数据,并实现线程的通信和栅栏同步。线程ID:线程在线程块中的线程号(唯一标识)
基于线程ID的复杂寻址,应用程序可以将线程块指定为任意大小的二维或三维数组,并使用2个或3个索引来标识每个线程。- 对于大小是(Dx,Dy)的二维线程块,索引为(x,y)的线程的线程ID为(x+y*Dx)
- 对于大小为(Dx,Dy,Dz)的三维线程块,索引为(x,y,z)的线程的线程ID为:(x+yDx+zDx*Dy)
- 类似于C语言二维数组、三维数组中通过元素下标计算元素位置的方法
Grid:线程块组成的线程网格(最多2^32 个blocks)
执行相同Kernel、具有相同维数和大小的线程块可以组合到一个网格中。这样单个Kernel调用中启动的线程数就可以很大。同一网格中的不同线程块中的线程不能互相通信和同步。Grid 是一个线程块阵列,执行相同的内核,从全局内存读取输入数据,将计算结果写入全局内存。Block ID:线程块ID
线程块ID是线程块在Grid中的块号。实现基于块ID的复杂寻址,应用程序可以将Grid指定为任意大小的二维数组,并用2个索引来标识每个线程块。对于大小为(Dx,Dy)的二维线程块,索引为(x,y)的线程块的ID为(x+y*Dx)。现已支持三维Wrap:线程束
一个线程块中连续的固定数量(32)的线程组。将线程块中的线程划分成wrap的方式是:每个wrap包含线程ID连续递增的32个线程,从线程0开始递增到线程31。Stream:CUDA的一个Stream表示一个按特定顺序执行的GPU操作序列。诸如kernel启动、内存拷贝、事件启动和停止等操作可以排序放置到一个Stream中。一个Stream包含了一系列Grids,并且可以多个Stream并行执行。
下图很形象的展示了CPU、GPU以及GPU内部grid、block、thread的层次关系
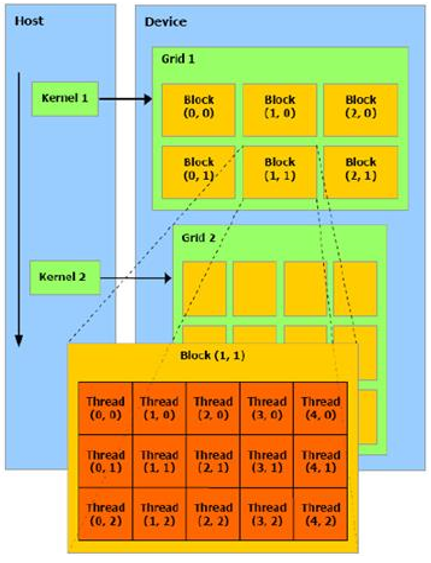
Grid、block 和 thread 的关系
在 CUDA 架构下,GPU芯片执行时的最小单位是thread。若干个thread可以组成一个线程块(block)。一个block中的thread能存取同一块共享内存,可以快速进行同步和通信操作。 每一个 block 所能包含的 thread 数目是有限的。执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一共享内存,因此无法直接通信或进行同步。不同的 grid可以执行不同的程序(kernel)。Grid是由线程块组成的网格。每个线程都执行该kernel,应用程序指定了Grid和线程块的维数,Grid的布局可以是一维、二维或三维的。每个线程块有一个唯一的线程块ID,线程块中的每个线程具有唯一的线程ID。同一个线程块中的线程可以协同访问共享内存,实现线程之间的通信和同步。每个线程块最多可以包含的线程的个数为1024个,线程块中的线程以32个线程为一组的Wrap的方式进行分时调度。每个线程在数据的不同部分并行地执行相同的操作。
CUDA处理流程
一个程序分为两个部份:Host 端和 Device 端。Host 端是指在 CPU 上执行的部份,而 Device 端则是在GPU上执行的部份。Device端的程序又称为kernel函数。通常 Host 端程序会将数据准备好后,复制到GPU的内存中,再由GPU执行 Device 端程序,完成后再由 Host 端程序将结果从GPU的内存中取回。CPU 存取 GPU 内存时只能通过 PCI-E 接口,速度有限。- 从系统内存中复制数据到GPU内存
- CPU指令驱动GPU运行;
- GPU 的每个CUDA核心并行处理
- GPU 将CUDA处理的最终结果返回到系统的内存
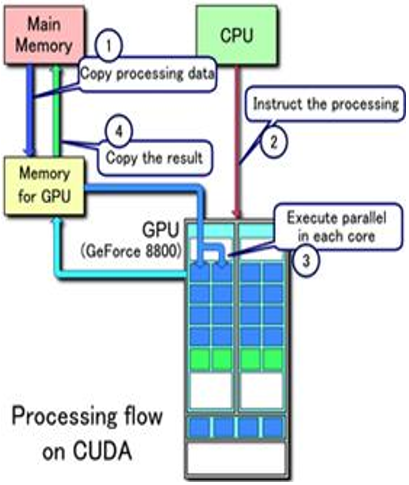
CUDA程序执行的基本流程
- 分配内存空间和显存空间
- 初始化内存空间
- 将要计算的数据从Host内存上复制到GPU内存上
- 执行kernel计算
- 将计算后GPU内存上的数据复制到Host内存上
- 处理复制到Host内存上的数据
CUDA编程模型
完整的CUDA程序包括主机端和设备端两部分代码,主机端代码在CPU上执行。设备端代码(kernel函数)运行在GPU上。其中一个kernel函数对应一个grid,每个grid根据需要配置不同的block数量和thread数量。- CPU作为主机端只能有一个+GPU作为设备端可以有多个+CPU主要负责逻辑处理+GPU负责密集型的并行计算
- CUDA包含两个并行逻辑层:block层和thread层。在执行时,block映射到SM、thread映射到SP(Core)
- 如何在实际应用程序中高效地开发这两个层次的并行是CUDA编程与优化的关键之一

